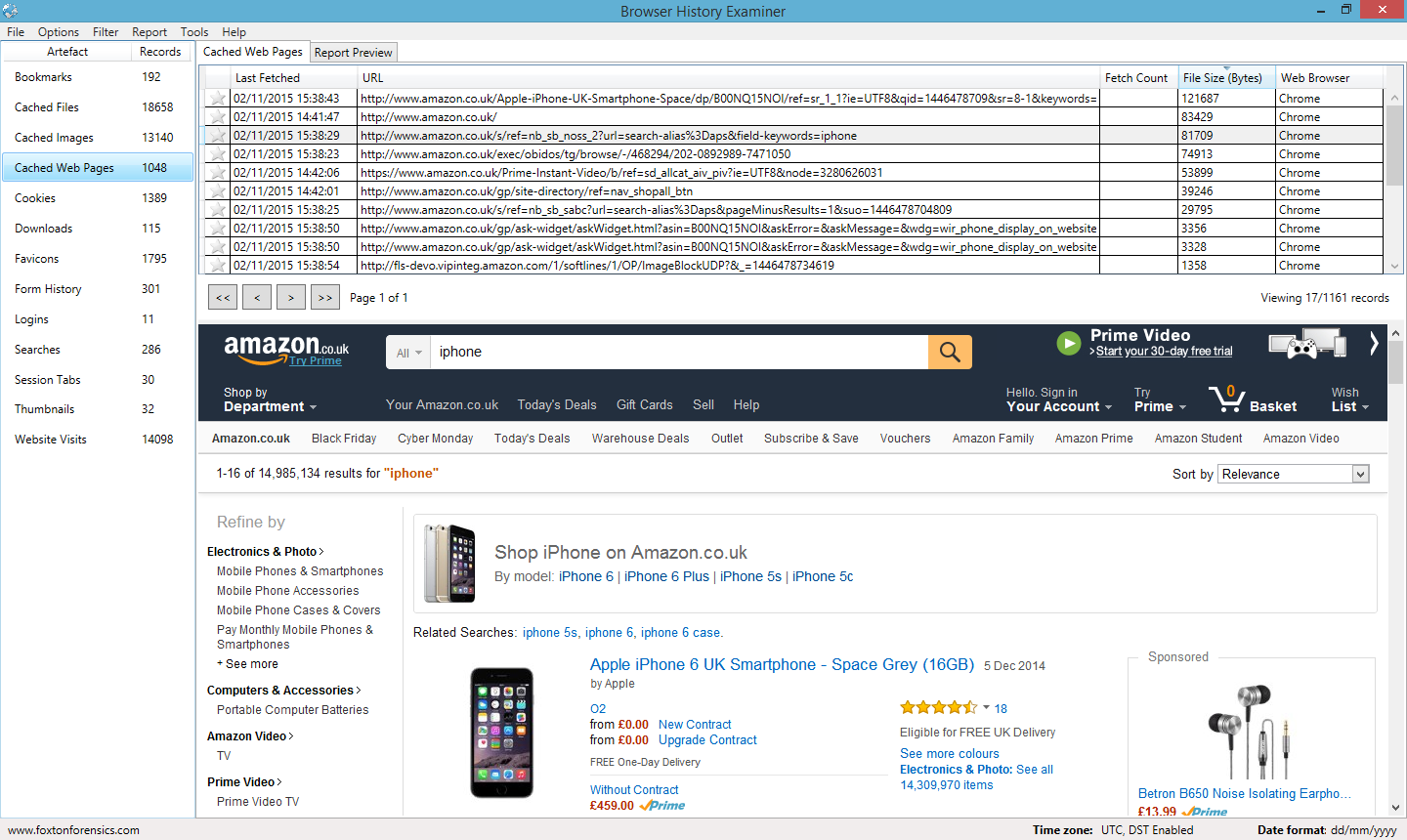
Web page reconstruction is a vital feature of any forensic software used for analysing browser history. Web page reconstruction is the process of using HTML and other resources stored in the web browser cache to rebuild a web page, allowing it to be easily viewed in the state it was originally seen by the user. This can be a great piece of visual evidence to include in a report, as we all know "
a picture is worth a thousand words".
We have had web page reconstruction functionality built into our tools
FoxAnalysis and
ChromeAnalysis for many years. However, when designing our new tools
Browser History Viewer (BHV) and
Browser History Examiner (BHE) we wanted to make this functionality easier to use and more reliable.
A great research paper on this topic from the University of Amsterdam in partnership with the Netherlands Forensic Institute is titled ‘
Reconstructing web pages from browser cache’. The research paper examined and tested the different methods of reconstructing a web page from the browser cache. Chapter 3.1 "Pre- or Post-processing" details the two methods available:
Pre-processing, occurs before the rendering browser has accessed the web page. It involves parsing all resource identifiers such as images, stylesheets, and scripts within the HTML document and updating their URLs to point to the local cached version. For example, the Google search results page includes the Google logo which is represented in the HTML document with the following image tag:
<img width="167" height="410" alt="Google" src="/images/nav_logo242.png">During pre-processing the cached image ‘
nav_logo242.png’ would be extracted from the browser cache, and the ‘
src’ URL would be updated to point to this local file.
Post-processing, occurs after the rendering browser has accessed the web page. It involves intercepting all HTTP requests for external resources from the rendering browser. If the requested resource is available within the browser cache then it is extracted and included in the response to the request. Post-processing therefore behaves in a similar manner to a proxy server.
The disadvantages of the pre-processing method are as follows:
1. It requires modifying a copy of the original evidence
2. It is hard to parse all resource identifiers, especially if JavaScript is used
3. Any resources identifiers which are not parsed may result in the original resources being downloaded over the internet
The second point is particularly important. The post-processing method does not suffer from this issue as it will capture all HTTP requests made by the rendering browser. Therefore, even if JavaScript causes further resources to be loaded into the page dynamically, these will be caught with post-processing.
Through testing with a proof of concept the research paper concluded that "
post-processing leads to more complete results without tampering with the evidence".
The research paper also examined existing tools capable of reconstructing web pages and at the time of writing (July 2013), stated that they all used the pre-processing method. This included NetAnalysis (Digital Detective), Internet Examiner v3 (SiQuest) and our own tools FoxAnalysis and ChromeAnalysis.
During testing against existing tools the research paper stated that "
comparing the results between this research and existing tools shows that the post-processing mechanism handles every resource request whereas pre-processing manages this only partly".
When developing BHV and BHE we chose to implement the post-processing method of reconstructing web pages in order to ensure a more reliable process. We also made it easier to view rebuilt web pages by separating them into a 'Cached Web Pages' tab and embedding a web browser within the application. The web browser uses the
WebKit rendering engine and is therefore capable of displaying modern web sites.
To see our web page reconstruction in action visit our
Downloads page for a free trial of Browser History Examiner, or to grab our free forensic tool, Browser History Viewer.